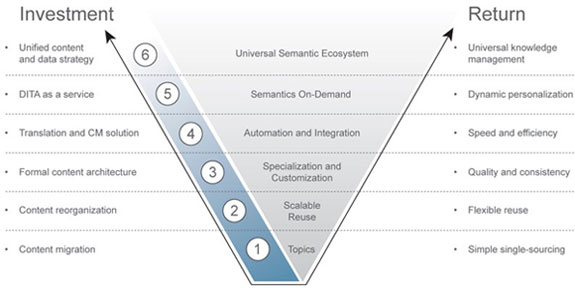
DITA, The Sequel: Refining your DITA workflow
The initial wave of DITA implementations is still building, but we are already seeing the early adopters move on to what I am calling DITA, The Sequel.
The initial wave of DITA implementations is still building, but we are already seeing the early adopters move on to what I am calling DITA, The Sequel.

In addition to mixed column and copyfitting, the shift from desktop publishing to structured authoring may result in the demise of the traditional index.
Originally published in tcworld e-magazine, July 2011
In Europe before the 1450s, books were precious, rare objects and were usually copied by hand over a period of months or years. Johannes Gutenberg and his printing press changed the economics of information distribution.
In this webcast, Simon Bate provides a “gentle introduction” to the DITA Open Toolkit (OT), the standard way to generate deliverables from DITA documents. This presentation shows how anyone can install the OT. A tour of the contents and how the plugin architecture works is included.
Over the weekend, a friend showed me an episode of a reality show that featured some commentary by a “style expert.” This expert offered his advice while dressed in an outfit that would work well as a costume in a production of Oliver Twist (and that’s being charitable).
I’m having some trouble with the idea of “extending DITA” outside the world of technical communication. DITA is obviously important in the right environment, but should we be advocating the use of DITA for more and more content?
Modifying FrameMaker cross-reference formats: it’s basic and one of the cool things about FrameMaker. But not if you’re editing DITA files using FrameMaker 9 or 10.
Rendering vector images (such as line art or charts) for PDF output through the DITA Open Toolkit can be tricky. You would think that an exported GIF of a vector image would display beautifully in the PDF—but you would be wrong.
I have struggled to understand the keyref and conkeyref features added in DITA 1.2.
It wasn’t until we started applying them to our proposal workflow that I finally understood them. I hope this use case also helps others.
“Content is an asset worthy of being managed,” says Scott Abel. I agree that good content is an asset. Bad content is a liability. It’s time to talk about the shameful underbelly of technical communication.
